Abstract
- 5초 이내 single 입력 이미지로부터 3D 모델 예측하는 최초의 lrm 제안함
- NeRF를 직접 예측하기 위해서 학습 가능한 5억개의 매개변수를 갖춤
- 확장성 뛰어난 Transformer 기반의 아키텍처를 제안함
- 대규모 다중 뷰 데이터에 대해 end-to-end 방식으로 train함
- 일반화 가능한 모델 → 고품질 3D 재구성 생성 가능
1. Intro
- 임의 개체의 single 이미지에서 즉시 3D 모양을 만드는 것
- 3D geometry의 ambiguity 대문에 초기 학습 기반 방법은 class 데이터 활용해서 특정 범주에서 잘 수행되었었음
- 형태별 최적화(NeRF 최적화) 일관된 geometry를 구성
- 근데 이게 느리고 비현실적임
- Transformer 는 확장성 뛰어나고 효과적임
- 3D 데이터 충분한 것, 대규모 훈련 framework 주어지면 하나의 image에서 객체 재구성하기 위한 일반적인 3D pretrain 이 가능하냐?
- 해당 논문에서는 single 이미지를 3차원으로 변환하기 위해서 LRM 제안
- 데이터 기반 방식
- Transformer 기반 Encoder-Decoder 아키텍처 채택함
- 입력: 이미지
- 해당 하나의 이미지를 3차원 표현의 NeRF로 회귀함
- Encoder: Dino
- 이미지 feature 생성
- Decoder: 삼중 평면 Transformer 임
- 2D image feature ⇒ 3D image feature(projection함)
- cross-attention 사용, self-attention 통해 공간적으로 구조화된 3차원 토큰 간 관계를 모델링
- 디코더의 출력 토큰 ⇒ 모양 변경 ⇒ 최종 3차원 feature map으로 업샘플링
- 이후 MLP를 사용해서 각 점의 3차원 feature를 디코딩 → 색상, 밀도 얻고 볼륨 렌더링 → 임의의 뷰에서 이미지를 렌더링
- 3차원 NeRF는 볼륨, 포인트 클라우드같은 표현에 비해 계산이 좀 수월 → 간결하고 확장 가능한 3D 표현
- LRM은 과도한 3D 인식 regularization이나 fine-tuning 없이 새로운 뷰에서 렌더링된 이미지와 실제 이미지 간 차이 최소화하면서 학습
- 모델이 학습에 매우 효율적이고 일반적임
2. Related Work
- single 이미지 ⇒ 3D reconstruction task를 위해 포인트 클라우드, 복셀, 메쉬 등의 암시적인 표현을 학습하는 다양한 방식들이 있음.
- categorical 한 reconstruction에서 많이 연구되었음
- categorical 에 구애받지 않는 방법은 일반화 잠재력을 보여주지만 세부 정보를 생성할 수 없는 경우가 대부분임
- 최근에는 pretrained Image/Language Model을 사용하는 추세임
- Make-It-3D 같이 CLIP 이미지 loss 통해서 기하학적, 의미적으로 그럴듯한 모양 생성함
- 그런데… LRM은 위의 것들이랑 다름
- 이미 사전학습된 모델은 이미 학습을 해서 처리를 해주는 거고 얘는 그렇지 않음
- 임의의 개체를 재구성하는 data-driven 방식임
- 생성 모델, pretrained multi modal에 의존하지 않음
- single image → 3D task를 해결하기 위해 생성 모델로의 접근들이 자주 있었음
- 근데 object의 texture, geometry, pose 등의 세부 정보를 train 하게 됨
- 문제: 이걸 잘 학습하려면 똑똑한 네트워크랑 아주 많은 3D 데이터가 필요
- 결론: 이런 방법의 대부분은 몇 가지 class에만 초점 맞추고 걍 대략적인 결과만 생성함
- GINA-3D가 대표적인 예시임
- Vision Transformer Encoder+cross-attention 적용
- 그러나 모델, 훈련도 규모 너무 작고 작업이 클래스별 생성에 초점을 맞춰서 한계가 많음
- MCC: 이건 data-driven 방식
- 일반화 가능한 Transformer 기반 Decoder 학습
- 입력 이미지, projection 안 한 포인트 클라우드에서 점유와 색상을 예측함
- 근데 처리는 가능한데 결과가 너무 매끄럽고 세부 정보가 손실됨
- multimodal 3D
- LRM은 3D를 새로운 양식으로 간주
- cross-attention → 2D feature map을 3D 로 바꿈
- 이런 방향으로 연구했던 최근 연구에는 ULIP이 있음
3. Method

- LRM에는 입력 이미지를 패치별 feature token으로 인코딩하는 이미지 인코더와 corss-attention을 통해 이미지 fature를 삼중 평면 토큰에 투영하는 이미지 3D decoder가 포함되어 있음
- output triplane tokens는 upsample되고 reshape되어서 최종적인 3차원 표현이 됨
- 3D point features를 query하기 위해 사용됨
- 최근에 3D point features는 MLP를 통과하여 Volume Rendering을 목표로 RGB와 density를 추정함
- training objectives와 데이터는 Sec. 3.4와 4.1에 묘사됨
3.1 Image Encoder
- RGB 이미지 주어짐
- pretrained ViT 적용 → 패치별 feature token으로 인코딩
- 이미지에서 두드러진 콘텐츠 구조, 질감에 대한 해석 가능한 attention 학습하는 self-diffusion model DINO 사용함
- Dino > ResNet, CLIP
- 결과적으로 ViT의 pre-defined된 patch-wise features를 모으는 class token [CLS]를 사용안 함
- 이러한 정보를 더 잘 보존하기 위해 전체 feature sequence 인 다음 h를 사용함

3.2 Image-To-Triplane Decoder
- 이미지와 카메라 feature를 학습 가능한 공간 위치 임베딩에 투영
- 삼중 평면 표현으로 변환하기 위해 Transformer Decoder를 구현
- 이 디코더는 필요한 기하학적 및 외관을 제공하기 위해 대규모 데이터로 훈련된 이전 네트워크로 간주될 수 있음
- 단일 영상 재구성의 모호성을 보완하기 위한 정보임
Camera Features
- 2D - 3D projection할 때, camera features가 필요함(intrinsic, extrinsic… 등등) 그래서 넣어준 값임
- 이게 실제 이미지와도 잘 매칭되어야 하는데 이걸 Decoder 내부에서 매칭을 시켜주기 위해 각 단계별로 넣어줌
- input 이미지의 camera feature c 를 4-by-4 camera extrinsic matrix E (camera와 real world transformation을 나타냄)를 평탄화해서 구성함
- 이것을 camera의 focal length인 foc, principal point pp와 합침
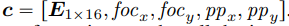
- 또한 모든 입력 카메라가 동일한 축(z축과 정렬된 룩업 방향)에 정렬되도록 유사도 변환에 의해 카메라 외부 E를 정규화
- LRM은 객체의 표준 포즈에 의존하지 않으며 접지 gt c는 학습에만 적용됨
- 정규화된 카메라 매개 변수를 조정하면 삼중 평면 기능의 최적화 공간이 크게 줄어들고 모델 수렴이 용이해짐(4.2절의 세부 정보 참조).
- 카메라 feature를 내장하기 위해 저희는 카메라 feature 을 고차원 카메라 내장 c-hat 에 매핑하는 다중 레이어 퍼셉트론(MLP)을 추가로 구현함
- 고유성(focal 과 keypoint)은 MLP 계층으로 전송하기 전에 이미지의 높이와 너비에 의해 정규화됨
- cross-attention에서는 image features와 camera modulation 간의 상관관계 를 모델링해주고 self attention에서는 같은 시퀀스 내의 상관관계를 모델링함
- 그러고 나서 camera modulation한 후에 MLP 처리함
Triplane Representation
- 요약하면 3차원 투영 Transformer Decoder에서 각 레이어마다 cross-attention, modulation 통해서 2d 이미지 feature를 3D 이미지 feature로 바꿔준다 뭐 그런 얘기임
- 우리는 3차원을 적용하기 위해 compact한 reconstruction 주제의 expressive feature respresentation으로서 이전 연구(Chan et al., 2022; Gao et al., 2022)를 따름.
- 3차원 T는 3개의 축을 따르는 feature planes T_XY, T_YZ, T_XZ로 이루어져 있음.
- 우리의 구현에서 각 평면은 (64 x 64) x d_T 차원임
- 64 x 64는 공간 해상도
- d_T는 feature channels의 수
- NeRF 객체 경계 상자 r[-1,1]의 모든 3D 포인트에 대해 각 평면에 투영하고 bilinear interpolation을 통해 해당 포인트 feature T_XY, T_YZ, T_XZ를 쿼리할 수 있으며, 이는 MLPnerf에 의해 NeRF 색상 및 밀도로 디코딩됨(Sec. 3.3).
- 3차원 표현의 T를 얻기 위해, 학습 가능한 spatial-positional embeddings (3x32x32)x d_D 차원의 f_init를 정의함.
- spatial-positional embeddings
- image-to-3D 지도
- cross-attention을 통해 image feature들을 찾는데 사용됨
- d_D
- transformer decoder의 숨겨진 차원임
- spatial-positional embeddings
- 걍 디코더에서 2d-to-3d 해주는데 그거에 대한 설명임..
- f_init안의 토큰들의 수는 (3x64x64) 최종 3차원 토큰들의 수보다 작음
- transformer f^{out}의 output을 최종 T로 upsample할 것임
- forward 과정에서
- camera features $\hat{c}$
- image features $[h_i]^n_{i=1}$
- 각 image-to-triplane transformer decoder의 각각의 레이어가 점진적으로 initial positional embedding $f^{init}$를 modulation과 cross-attention을 최종적인 3차원 features로 업데이트해나감
- 두 가지 다른 조건부 연산을 적용하는 이유는 카메라가 전체 모양의 방향과 왜곡을 제어하는 반면 이미지 특징은 삼각형 평면에 포함되어야 하는 세부적인 기하학적 및 색상 정보를 전달하기 때문임
- 두 연산에 대한 자세한 내용은 아래에 설명되어 있
Modulation with Camera Features
- 위에 있는 camera features 를 연산시켜주는 과정임..
- camera modulation은 DiT로부터 영감을 받았음
- DiT
- Transformer + Diffusion + AdaLN 사용한 것
- adaLN(adaptive layer norm)을 구현함
- 목표: image latents를 timesteps와 classlabels 사용해서 denoise함
- DiT
- $f_j$를 transformer의 벡터들의 시퀀스라고 가정
- camera feature c 의 modulation function을 $ModLN_c(f_j)$ 라고 정의

- r, beta는 $MLP^{mod}$으로부터의 scale, shift output임
- LN은 Layer Normalization
- 각 modulation은 다음에 특정될 각 attention sub-layer에 적용된다
- 처음에 modulation하기 위해서 MLP를 쓰긴 했는데 이게 AdaLN 기법의 영향을 받아서 scale, shift라는 변수를 아웃풋으로 받음
- 그래서 이걸 transformer에 넣었던 시퀀스를 LN한 값과 잘 곱하고 더하기 linear regression 처럼 수식 써서 한 것으로 보임
Transformer Layers
- 각각의 Transformer layer는 cross-attention sub-layer, self-attention sub-layer, multi-layer perceptron sub-layer(MLP)를 포함함
- MLP에서 각 sub-layer로의 input tokens 이 camera features에 의해 modulate됨
- feature sequence $f^{in}$이 transformer layer의 input이라고 가정
- $f^{in}$이 3차원 hidden features라고 할 수 있겠음
- 이유: 이 features가 최종 3차원 features T 와 대응되기 때문임
- Fig. 1의 디코더 파트에서 본 것처럼, cross-attention module은 처음으로 3차원 hidden features $f^{in}$ 에서 image features $[h_i]^n_{i=1}$ 까지 참여한다.(이 과정을 다 겪는다 뭐 그런 소리같음)
- 이게 image 정보를 3차원과 연결시키는 데 도움을 줌
- 이 논문에서는 2D 이미지들과 3D 차원의 숨겨진 features 간의 어느 공간적 정렬도 명쾌하게 정의하지 않음
- 그러나 3D를 독립적인 modality로 간주하고 model이 2D-to-3D 상관 관계를 스스로 학습하도록 함
- 업데이트된 3차원의 hidden features는 self-attention sub-layer로 통과될 것임
- self-attention sub-layer는 공간적으로 구조화된 3차원 항목들간의 intra-modal 관계들을 더 잘 모델링함
- 그 후에, 원래 Transformer design 처럼 MLP sub-layer($MLP^{tmf}$) 가 바로 뒤에 오게 됨
- 마지막으로 출력된 3차원 feature $f^{out}$는 다음 Transformer layer의 입력이 될 것
- 이러한 설계는 Perceiver 네트워크(Jaegle et al., 2021)와 유사하며, 우리의 모델은 잠재적인 bottleneck 현상에 입력을 projection하는 대신 attention layer에 걸쳐 고차원 표현을 유지함
- 그러니까 bottleneck 구조를 사용하는 대신 attention 썼다는 말을 이렇게 표현한 것
- bottleneck 쓰면 데이터 압축이 되서 정보 소실이 일어나게 됨 → 이런 부분 없다
- 전체적으로 이 프로세스를 각 레이어에서의 각 j 번째 3차원 entry로서 표현하면 다음과 같다.
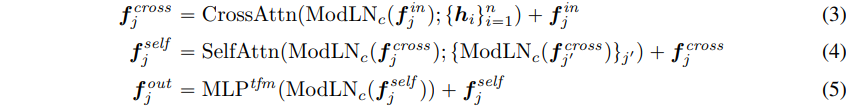
- sub-layers(i.e., CrossAttn, SelfAttn, $MLP^{tfm}$) 안의 ModLN operators는 layer normalization과 modulation $MLP^{mod}$ 안의 다른 학습 가능한 파라미터들 set 을 사용한다.
- 이것에 대한 부연설명은 없음
- transformer layer들은 연속적으로 처리됨.
- 결국 모든 transformer layer들 후에 우리는 decoder의 output이면서 마지막 layer로부터 3차원 features $f^{out}$를 얻게 됨.
- 마지막 output은 학습 가능한 deconvolution layer로부터 upsample되고 최종 3차원 표현의 T로 형태가 바뀜
3.3 Triplane-NERF
- triplane-NeRF 공식을 활용하고 3차원 표현의 T로부터 검색된 point features로부터의 RGB와 density 를 예측하기 위해서 $MLP^{nerf}$를 구현했음
- $MLP^{nerf}$는 ReLu activation과 multiple linear layers을 가지고 있음.
- $MLP^{nerf}$의 output 차원은 4
- 처음 3차원들은 RGB 색상과 field의 density와 대응하는 마지막 차원임
3.4 Training Objectives
- LRM은 single input 이미지로부터 3D shape를 만들어줌
- 추가적인 side views를 레버레지해서 학습 과정 중에 reconstruction을 지도함
- training data에서의 각 shape을 목표로, 우리는 supervision을 위해 랜덤하게 선택된 (V-1) side view들을 고려함
- V개의 render된 뷰들 $\hat{x}$ 와 ground-truth 뷰들 $x^{GT}$ 사이의 간단한 이미지 reconstruction objectives를 적용
- 더 정확하게는 모든 input 이미지 x를 목표로 우리는 다음의 Loss를 최소화함

- $L_{MSE}$는 정규화된 픽셀단위 L2 Loss
- $L_{LPIPS}$는 인지된 이미지 패치 유사도임
- GAN이나 생성 쪽에서 사용하는 loss
- lambda는 맞춤 가중치
4. Experiments
4.1 Data
- LRM은 Objaverse, MVImgNet 으로부터의 충분한 3D data에 의존함
- 일반화된 cross-shape의 3D prior를 학습하기 위해 합성의 3D assets과 실세계에서의 object들의 video 들로 구성됨
- Objaverse의 각 3D asset에 대해, 우리는 real world의 box [-1,1]로 모양을 정규화하고 임의의 포즈로 객체를 향하는 동일한 카메라로 32개의 랜덤 뷰를 렌더링함
- 렌더링된 이미지의 해상도는 1024x1024이고 카메라 포즈는 반경 r1.5, 3.0s , 높이 범위 r'0.75, 1.60s 의 공에서 샘플링됨
- 각 비디오에 대해 데이터세트에서 추출된 프레임을 활용합니다. 해당 프레임의 대상 모양은 임의의 위치에 있을 수 있으므로 예측된 개체 마스크4를 사용하여 모든 프레임을 자르고 크기를 조정하여 개체가 결과 프레임의 중심에 오도록 함
- 이에 따라 카메라 매개변수를 조정함 우리의 방법은 배경을 모델링하지 않으므로 Objaverse에서 순수한 흰색 배경으로 이미지를 렌더링하고 기성 패키지4를 사용하여 비디오 프레임의 배경을 제거하였음
- 전체적으로 우리는 훈련을 위해 730,648개의 3D assets과 220,219 개의 비디오를 사전 처리
- 임의 이미지에 대한 LRM의 성능을 평가하기 위해 Ob-javerse(Deitke et al., 2023), MvImgNet(Yu et al., 2023), ImageNet(Deng et al., 2009), Google Scanned Objects에서 새로운 이미지를 수집(Downs et al., 2022),
- Amazon Berkeley Objects(Collins et al., 2022)는 실제 세계에서 새로운 이미지를 캡처하고 재구성을 위해 Adobe Firefly5로 이미지를 생성
4.2 Implementation Details
생략
4.3 Results
4.3.1 Visualization


- 그림 2는 단일 이미지에서 재구성된 모양의 몇 가지 예를 시각화함. 전반적으로 결과는 뚜렷한 질감을 지닌 다양한 피사체의 실제, 생성 및 렌더링된 이미지를 포함하여 다양한 입력에 대해 매우 높은 충실도를 보여줌. 복잡한 형상이 올바르게 모델링되었을 뿐만 아니라 (예: 의자, 깃발, 닦음) 나무 공작의 질감과 같은 고주파수 세부 사항도 모델링되었음.
- 비대칭 예제에서도 LRM이 모양의 의미적으로 합리적인 폐색 부분 추론 가능했음
- 효과적인 cross shape 사전 학습이 되었음
- 2D diffusion model로 다중 뷰 이미지 생성 → sota single image를 3D reconstruction함
- 동시 작업인 One-2-3-45와 비교함
- LRM이 훨씬 더 선명한 디테일, 일관된 표면 생성함
4.3.2 Limitations

- 폐색된 영역에 대해 흐릿한 텍스처 생성하는 경향
- 원인: single image → 3D 자체가 확률론으로의 접근임
- 평균에 가까운 영역들만 잘 표현하고 그렇지 않을 경우 생성이 잘 안 됨
- 원인: single image → 3D 자체가 확률론으로의 접근임
- 추론 시간 동안 고정된 camera intrinsic, extrnsic parameter set을 테스트 이미지에 할당함
- 카메라 매개변수가 실제와 일치가 잘 되지 않게 됨 → 왜곡된 형태 재구성
- 배경이 없는 사물의 이미지만을 다룸
- 배경, 복잡한 장면 처리하는 것은 이 작업 범위 벗어남
- 빛나는 금속, 세라믹 같은 뷰 의존적 외관 충실하게 재구성 못함
- NeRF의 뷰 종속 모델링을 생략함 (기존에 NeRF는 이걸 잘 해서 정반사되는 사물들도 잘 표현했었음)
5. Conclusion
- LRM은 training, inference에 효율적
- 앞으로의 연구 방향
- 모델과 학습 데이터 확장
- 가장 간단한 transformer 기반의 디자인과 minimal regularization
- LRM은 쉽게 크게 확장 가능한 모델
- 더 큰 이미지 인코더 적용
- 더 많은 attention layer 추가
- 더 크고 더 유능한 네트워크로 쉽게 확장 가능함
- 이미지-triplane decoder에 연결, 3차원 표현의 해상도 높임
- 다중 뷰 이미지만 필요(supervised 목적)
- multimodal 3D 생성 모델로의 확장
- 먼저 2D 이미지 생성 위해 Text-Image 생성 모델 활용 → 새로운 3D shape 생성하기 위한 경로 구축
- 그렇지만 3차원 triplane 제안
- 효율적인 text-3D 생성, 편집 가능하게 하기 위해서 언어 설명, 3D직접 연결하는 데 적용 가능
- 모델과 학습 데이터 확장
#3D #Transformer #NeRF
참고:
AI 논문 분석 : LRM, 5초 안에 단일 이미지에서 3D로
안녕하세요. 오늘은 AI 분야 최신 논문을 살펴보는 네 번째 시간입니다. 요즘 생성형 AI 기술의 발전이 매우 빠른 것 같은데요. 저번 시간에 다룬 실시간 수준 스테이블 디퓨전 이미지 생성에 이
fornewchallenge.tistory.com
https://paperswithcode.com/paper/lrm-large-reconstruction-model-for-single
'SOTA 논문 리뷰' 카테고리의 다른 글
| Structure from Motion 리뷰 (0) | 2024.01.31 |
|---|---|
| LDC: Lightweight Dense CNN for Edge Detection 논문 리뷰 (0) | 2024.01.05 |